La BIU Santé profite de la période estivale pour revenir sur un projet important de 2017-2018, le versement de certaines de ses numérisations sur Wikimedia Commons.
Une affaire de sources
Dans sa banque d’images et de portraits, la BIU Santé propose plus de 230.000 images, téléchargeables gratuitement. Elles sont pour la plupart libres de droits, et réutilisables sous la licence Etalab. Ces clichés sont issus des numérisations réalisées pour notre bibliothèque numérique Medic@ (plus de 4,5 millions de pages de textes en ligne), de nos collections iconographiques et des fonds d’images de nos partenaires.
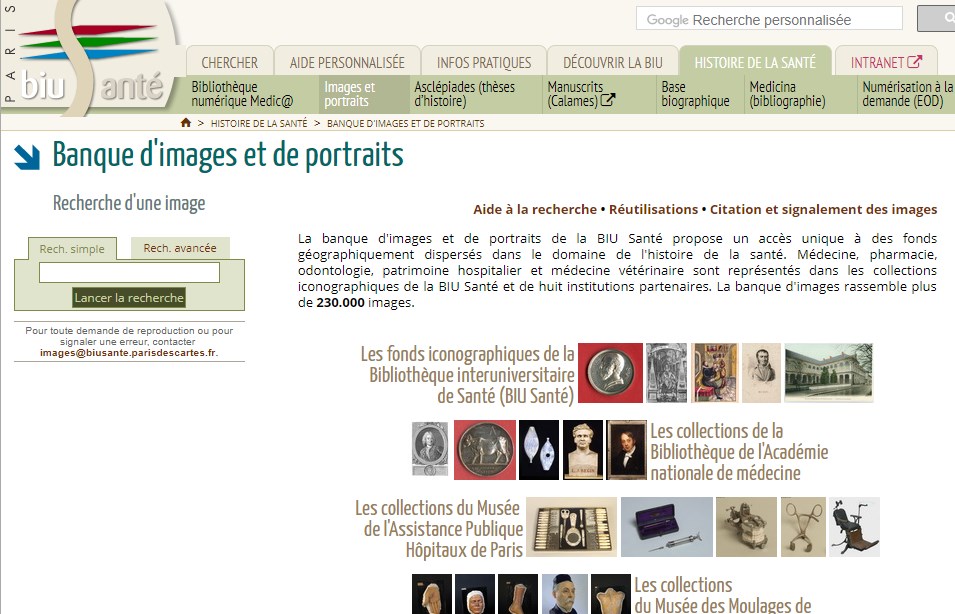 Jusqu’à présent, ces images n’étaient consultables que via le site de la BIU Santé. Ce qui ne les empêchait pas d’être abondamment réutilisées sur des sites tiers, comme Wikipédia ou Pinterest (où la BIU Santé possède d’ailleurs un compte ;-). Quand le projet démarre, près de 300 images issues de la BIU Santé sont déjà repérées sur Commons. Ces emprunts en ligne ne sont pas toujours accompagnés des (bonnes) mentions de sources. Cela va à l’encontre de la licence Etalab choisie par la bibliothèque, mais c’est surtout préjudiciable pour les documents eux-mêmes. En perdant leur mention d’origine, ils perdent une partie de leur histoire et de leur valeur.
Jusqu’à présent, ces images n’étaient consultables que via le site de la BIU Santé. Ce qui ne les empêchait pas d’être abondamment réutilisées sur des sites tiers, comme Wikipédia ou Pinterest (où la BIU Santé possède d’ailleurs un compte ;-). Quand le projet démarre, près de 300 images issues de la BIU Santé sont déjà repérées sur Commons. Ces emprunts en ligne ne sont pas toujours accompagnés des (bonnes) mentions de sources. Cela va à l’encontre de la licence Etalab choisie par la bibliothèque, mais c’est surtout préjudiciable pour les documents eux-mêmes. En perdant leur mention d’origine, ils perdent une partie de leur histoire et de leur valeur.
Suivant l’exemple d’autres institutions culturelles (comme la Wellcome Library ou le muséum de Toulouse), la BIU Santé s’est donc interrogée sur l’opportunité de déposer elle-même ses images sur Wikimedia Commons. Pour qu’elles soient plus visibles et plus facilement accessibles aux internautes du monde entier. Et pour être sûr que les références et mentions de sources soient bien rédigées (on n’est jamais mieux servi que par soi-même !).
On commence modestement
Par l’entremise de Sylvain Machefert (merci à lui), les équipes de la BIU Santé prennent contact avec l’association Wikimédia France. Une convention est alors signée, pour le dépôt d’un premier lot d’images, ayant valeur de test. On choisit de se faire la main sur les portraits présents dans la banque d’images. Ils ont l’avantage de constituer un ensemble clairement défini, lié en outre à des notices d’autorité (noms de personnes). Édouard Hue, concepteur d’un outil de versement d’images sur Commons (ComeOn!) et bénévole de l’association, travaille avec la bibliothèque pour ce premier essai.
Notre lot de portraits est donc constitué de 3775 fichiers. 3203 étaient liés à une notice de notre base biographique (en l’occurrence, le nom de la personne représentée par le portrait). Dans cette notice figuraient notamment les informations élémentaires que sont le patronyme et les dates de naissance et de mort. Avec parfois plusieurs portraits pour une même personne. Au final, les 3203 fichiers correspondaient en fait à 1541 autorités / personnes distinctes.

Pour que le versement soit le plus complet possible, il a été décidé de lier nos métadonnées avec des référentiels extérieurs. OpenRefine a été utilisé pour ce travail de pré-alignement de nos données.
Le référentiel le plus logique à viser pour un versement sur Commons était bien évidemment Wikidata. Pas de chance, aucun connecteur fiable n’existait à l’époque pour pré-aligner des données sur Wikidata à partir d’OpenRefine 2.6. Qu’à cela ne tienne, les bibliothécaires se sont tournés vers VIAF, autre grand référentiel, bien adapté pour des portraits, faciles à lier à des notices d’autorité. Les identifiants VIAF trouvés servent de données-pivots et permettent de récupérer des identifiants Wikidata dans un second temps.
À la recherche des identifiants VIAF…
Trois données issues de notre base Biographie ont été prises en compte pour les tentatives de « réconciliation » avec VIAF : le patronyme, et les dates de naissance et de mort.
- 2451 portraits ont pu être préalignés avec une autorité présente dans VIAF, à partir des recommandations fournies par OpenRefine 2.6 ;
- 535 ont pu être alignés « à la main » à une autorité VIAF, OpenRefine n’ayant pas réussi à fournir de pré-alignement satisfaisant ;
- 217 n’ont pas pu être reliés à une autorité VIAF ;
Le temps de traitement pour ce préalignement : environ 250 autorités examinées par heure (ce qui inclut le temps de recherche manuel dans VIAF quand OpenRefine ne proposait aucune piste).
Jugeant avoir trouvé le maximum d’identifiants VIAF possible avec leurs données biographiques, les bibliothécaires ont ensuite cherché des équivalences avec le système d’identifiants de Wikidata.
…puis des identifiants Wikidata
Le cœur du projet VIAF n’est pas tant de maintenir un système d’identifiants liés à des données biographiques que de mettre en correspondance les données d’autorité de grands référentiels mondiaux.
C’est pourquoi l’OCLC, qui gère le service VIAF, met à disposition les concordances établies par différents moyens, notamment une collection de web services. On peut ainsi récupérer, grâce à un matricule VIAF, les identifiants de l’autorité correspondante dans divers référentiels. Par exemple, ceux d’Olaf Stapledon.
Pour une requête unique, c’est suffisant. Dans le cadre de notre projet de versement, où nous attendait un travail de mise en correspondance plus conséquent, nous avons préféré nous tourner vers les dumps que propose VIAF, où sont listées, dans de volumineux fichiers (plusieurs gigas après décompression !), toutes les équivalences composant cette base.
![]() Une fois le dump de liens VIAF téléchargé, dans son format le plus simple, nous en avons intégré le contenu dans une base de données où nous avons également inséré nos données biographiques alignées avec VIAF. Quelques requêtes SQL plus tard, nos identifiants VIAF étaient conjoints à leur homologues Wikidata.
Une fois le dump de liens VIAF téléchargé, dans son format le plus simple, nous en avons intégré le contenu dans une base de données où nous avons également inséré nos données biographiques alignées avec VIAF. Quelques requêtes SQL plus tard, nos identifiants VIAF étaient conjoints à leur homologues Wikidata.
Notre jeu de données était désormais complet et nous pouvions préparer le versement, d’abord en en précisant le format, ensuite en confectionnant les fichiers nécessaires à l’outil ComeOn!
Trousser un format de versement dans Commons
Structurer les métadonnées
Un réservoir de fichiers multimédia nécessite des métadonnées. Dans Wikimedia Commons, ces métadonnées prennent pour l’essentiel la forme de pages rédigées en wikicode, un type de syntaxe largement répandue sur les applications utilisant un moteur Mediawiki, à l’instar des différentes Wikipédia. Verser en masse dans Commons, c’est donc uploader des fichiers, mais également créer les pages en wikicode qui les accompagneront et porteront leurs métadonnées.
La méthode est ici de définir un modèle de page en wikicode que l’on déclinera pour chacun des objets composant le versement en y injectant les métadonnées. C’est précisément ce que permet de faire l’outil ComeOn!, qui opère simultanément sur un jeu de métadonnées, un template conçu pour générer du wikicode et un jeu de fichiers à verser.
Pour définir notre modèle de page en wikicode, nous avons cherché à utiliser au maximum des structures de données ayant déjà cours sur Commons, ce qui en améliore la lisibilité et en favorise la valorisation. En effet, des mises en forme spéciales sont attachées à ces structures et leur (relative) normalisation autorise l’exploitation des données qui y sont stockées par des processus automatisés.
Nous avons donc fouillé dans la collection de templates wikicode que propose Commons pour y trouver les mieux adaptés à notre projet. Finalement, nous utiliserions principalement les structures Artwork, Creator et Depicted Person dans les pages accompagnant nos images.
Pour fixer les idées, voici à titre d’exemple la forme générale de la structure en wikicode « Artwork » :
{{Artwork
|artist = DATA
|author = DATA
|title = DATA
|description = DATA
|date = etc.
|medium =
|dimensions =
|institution =
|department =
|place of discovery =
|object history =
|exhibition history =
|credit line =
|inscriptions =
|notes =
|accession number =
|place of creation =
|source =
|permission =
|other_versions =
|references =
|wikidata =
}}
Il y eut alors une étape de mise en correspondance précise de nos données et de ces structures. Par exemple, nous avons choisi d’indiquer l’identité de la personne représentée sur l’image au moyen d’une structure « Depicted person » insérée dans la propriété « description » de la structure « Artwork ».
Pour tester et valider ces choix, des pages d’exemple ont été créées manuellement sur Commons, que nous avons fait évoluer petit à petit.
Catégoriser les fichiers sur Commons
En complément de ces choix de structuration des métadonnées, chaque fichier versé devait être rattaché à des catégories pertinentes sur Commons (au sujet desquelles existe entre autres cette introduction), ce qui se traduit techniquement par l’ajout de balises spécifiques en wikicode dans la page d’accompagnement.
Cette catégorisation a été rendue possible par la collaboration avec Édouard Hue qui a abouti à la mise au point de tableaux de concordances où nos données concernant les techniques utilisées par les artistes, le support matériel de l’œuvre, la fonction des auteurs d’images et la nature du document étaient appariées avec des catégories Commons. Suivant la pratique « wikimédienne », ces choix ont été documentés en ligne, sur une page spéciale de Commons.
Où l’on met la dernière main aux fichiers
Après cet ultime alignement de données, et une fois validé le mapping avec les structures en wikicode que nous avions choisies, nous avons pu parfaire le code de génération de pages élaboré par Édouard Hue lors de nos premiers essais. Ce code de génération est en fait un script suivant la syntaxe du moteur de templates Velocity, laquelle est bien documentée.
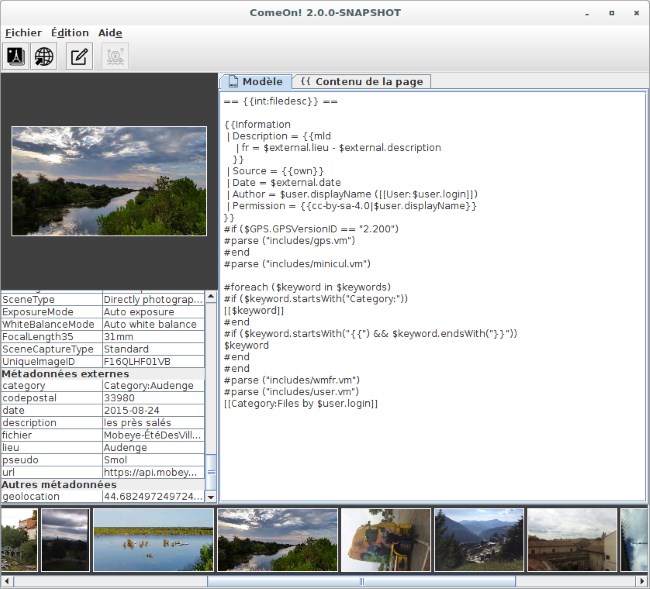
Le script Velocity est utilisé par ComeOn! pour générer du wikicode et le transmettre aux serveurs de Commons. Mais comment lui transmettre les données à intégrer ? Nous avons suivi la méthode recommandée pour les versements en masse, la création, à partir d’extractions de notre base de données, d’un fichier CSV. Nous avons un peu tâtonné pour aboutir à un format de fichier CSV s’harmonisant au fonctionnement de ComeOn! et du script Velocity. Dans ce fichier UTF-8, les valeurs, séparées par des virgules, ont dû être encadrées chacune d’apostrophes et, à l’intérieur de ces valeurs, les guillemets ont dû être « échappés » par des barres obliques inverses.
Enfin, nous avons préparé les fichiers images eux-mêmes, en les renommant en masse (au moyen de l’outil Bulk Rename Utility). Notre but ici était de donner à nos fichiers un nom significatif pour les utilisateurs de Commons, tout en mentionnant notre identifiant maison pour faciliter le suivi. Nous désirions aussi nous conformer aux préconisations de Commons en la matière.
Le(s) versement(s)
Tous les éléments étant prêts, nous avons ensuite effectué nos premiers versements de test avec ComeOn!, que nous avons connecté à Commons au moyen d’un compte Wikimedia certifié. La communauté Commons utilise l’outil OTRS pour offrir de telles authentifications. Cela nous a permis d’utiliser sur nos pages des bandeaux garantissant la provenance des images et donnant un poids plus important à nos licences d’utilisation.
Nous avons augmenté progressivement la taille des lots d’images envoyés et avons finalement opté pour des versements de 300 images. Ces versements modestes ne prenaient que 10 à 20 minutes et ont permis de faire un suivi continu du versement qui s’est étalé sur trois jours.
Au final, les portraits déposés sont consultables sur Commons à cette adresse.
Le travail de la communauté
La première chose à faire est d’observer comment les images de la BIU Santé vont vivre leur vie propre. Vont-elles être réutilisées ? Des métadonnées nouvelles vont-elles être rajoutées par la communauté (sur nos portraits anonymes par exemple) ? Des statistiques de consultation sont d’ores et déjà consultables ici.
Lorsque Wikidata est mentionné dans la liste des utilisations de l’image, cela veut généralement dire que notre image est la représentation canonique du sujet, celle qui apparaîtra par défaut sur les diverses Wikipédia.
Des statistiques complémentaires sont disponibles ici (il est parfois nécessaire d’appuyer sur le bouton «Show page views» de l’onglet «Process» pour avoir des comptes détaillés). En particulier, on y trouve dans ce deuxième outil les sous-totaux, par wiki, du nombre d’utilisations des images.
Les mêmes liens, en limitant cette fois la collection aux seuls fichiers versés par la BIU Santé en juin :
 On s’aperçoit ainsi que les wikipédiens s’approprient peu à peu les fichiers et les réutilisent pour illustrer des pages de l’encyclopédie. Le travail s’organise aussi sur les listes de diffusion.
On s’aperçoit ainsi que les wikipédiens s’approprient peu à peu les fichiers et les réutilisent pour illustrer des pages de l’encyclopédie. Le travail s’organise aussi sur les listes de diffusion.
Des erreurs nous sont signalées : fichiers encore sous copyright déposés indûment, erreurs dans les métadonnées (et notamment dans les personnes représentées). Autant de corrections qui sont immédiatement reportées dans notre propre banque d’images.
À l’inverse, quid des modifications qui interviendront dans les métadonnées de notre banque d’images ? Comment les répercuter en ligne sur les images que nous avons uploadées ?
Et maintenant, la suite ?
Grâce à l’aide d’Édouard Hue, les équipes de la BIU Santé disposent désormais d’une petite expérience en matière de dépôt d’images sur Commons. Comment tirer parti de tout ce travail ?
La suite la plus logique consisterait à verser davantage d’images. Sur les 230.000 fichiers de la banque d’images, seuls 3775 ont été déposés. Parmi ces portraits, demeurent encore quelques illustres inconnu(e)s, appel aux amateurs pour les identifier (vive le crowdsourcing !).
Sur les listes de discussion wikipédiennes, plusieurs suggestions ont été émises :
- Catégoriser les fichiers déposés.
- Si ce n’est pas déjà le cas, lier les images déposées aux pages correspondantes de Wikipédia / Wikidata. Et créer les pages correspondantes si elles n’existent pas, notamment pour les femmes portraiturées, toujours sous-représentées dans l’encyclopédie (voir le projet des sans pagEs). Pour booster les choses, la BIU Santé réfléchit d’ailleurs à organiser un atelier, pendant lequel des bénévoles pourraient profiter de notre salle de formation pour agrémenter des pages Wikipédia avec certains de nos portraits.
- Plus original, localiser et lier les sépultures des personnes portraiturés (avis aux taphophiles !).
Bref, le travail (collaboratif) ne fait que commencer !
David Benoist & Olivier Ghuzel
En savoir plus
Accéder aux images de la BIU Santé déposées sur Wikimédia Commons
Présentation du projet aux Journées Wikimédia Culture et Numérique 2019
Une réflexion sur « Les portraits de la BIU Santé dans Wikimédia Commons »